- Gepost von: Kevin Pilch
- Datum: 18 Dec, 2023
- Kategorie: Data Engineering
Introduction
One of our clients, an energy company with millions of customers, runs and maintains dozens of applications and data pipelines that process hundreds of millions of energy consumption meter readings daily. Historically, the development and testing of these applications involved setting up and managing full test environments, frequently inserting fresh test data that was pulled from production systems. This created strong dependencies on the capacity of other teams and slowed down everyone involved.
In a bid to enhance efficiency and foster a culture of rapid, reliable delivery, the customer recently embarked on a DevOps journey. This transformative journey involves restructuring their operations and process flows to fully embrace Continuous Integration/Continuous Delivery (CI/CD) setups. This shift is not without its challenges; one of their main concerns was finding a reliable and scalable solution to the time-consuming task of constantly pulling fresh data from production systems for testing purposes. To solve this issue, we leveraged the utilisation of synthetic test data.
Harnessing the Power of Python’s Faker Library
Python’s Faker library is a powerful tool that allows developers to generate fake data — be it text, numbers, addresses, or even dates — which can be particularly useful for testing, filling databases, and creating anonymized data sets.
In our case, we initially built a Python class to generate JSON-formatted pseudo random meter reading data as it would come in from the customer’s smart energy meters. Some of the challenges we faced were
- Making sure that related data, such as different IDs belonging to the same entity, e.g. a customer ID and the related energy meter ID(s), will be consistent for each entity every time new data is generated
- Coming up with a solution so that the generated energy meter reading values will increase over time to mimic actual energy consumption
Overcoming the first challenge: Seeding the pseudo-RNG
Conveniently, Faker provides a seed() method, which seeds the underlying shared random number generator. When using a consistent seed value, a subsequently called method to generate one or more values will always produce the same results.
To tackle the first challenge of ensuring consistency in related data, we use customer IDs as seed values. This approach guarantees that every time we generate data, the same customer ID will yield the same underlying ID values, such as energy meter IDs, thereby preserving the relational integrity of our synthetic test data.
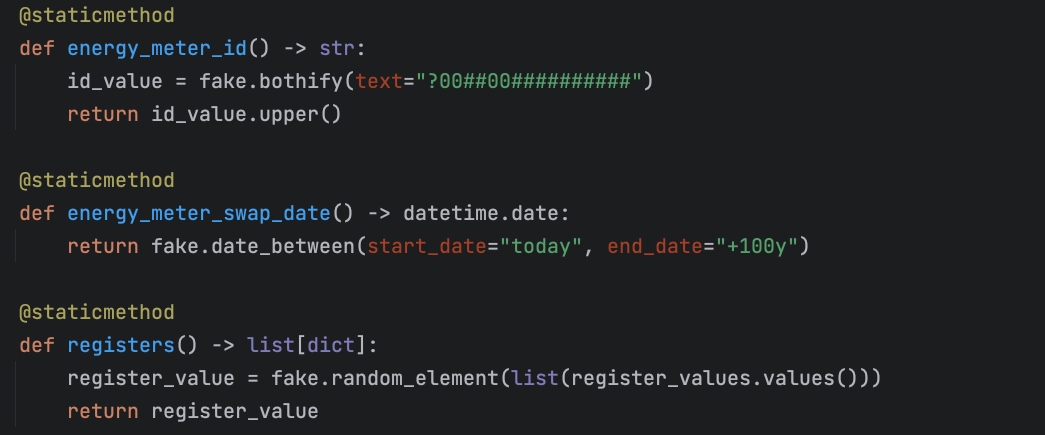
Overcoming the second challenge: Building a custom provider
In Faker, “providers” are the core components responsible for generating fake data. They encompass a variety of categories, such as ‘address’, ‘company’, ‘internet’, etc. Each provider comes with numerous methods that produce different types of fake data relevant to their category. For instance, the ‘address’ provider offers methods for generating street names, city names, zip codes, and so on.
Custom providers in Faker allow you to meet specific project requirements that may not be covered by the default providers. By creating your own providers, you can generate highly targeted and project-specific fake data, making your testing or data filling efforts more realistic and relevant. By creating a provider that generates reading values based on the current or a passed datetime-object, we can generate reading values that increase over time. To make this provider more realistic and not generate the same reading values for all energy meters on a given date, we created yet another provider that generates a random reading factor 0 < x < 10 for each energy meter, using the energy meter ID as a seed.
Even though these challenges do not reflect the full complexity of our solution, they are good examples of Faker’s versatility to build solutions that are custom-tailored to your projects. By subclassing the original data generator class, over time, we added support for more and more energy consumption data formats as needed for different teams and applications.
Distributing and Scaling the Solution
To provide the newly created Python package to users throughout the organisation, we dockerized it and pushed it to the client’s GitLab container registry. The idea was to use it as a base image and then have users add the necessary code to put the generated data into whatever storage that they needed for their tests. As it turns out, by far not everyone in the organisation knew how to do that in Python, as some other teams used different languages for their solutions.
To solve this challenge indefinitely, we added some very simple FastAPI endpoints to our image, thus making it fully compatible with pretty much every language, as well as GitLab CI pipelines. Users can now generate test data locally, in CI testing jobs and even distribute the solution to test environments.
By leveraging the simplicity of Docker and the power of FastAPI, we managed to turn a complex problem into a scalable, user-friendly solution that could be widely adopted within the organization. This not only boosted the speed and efficiency of testing but also contributed to a more cohesive and collaborative technology culture.
Conclusion
In conclusion, our innovative solution has vastly improved the way the client can test applications. By utilizing the Python Faker library, FastAPI, and Docker, we have made the process of generating infinite amounts of test data in different formats a breeze. This solution eliminates the need for constantly pulling new test data from production systems and reduces dependencies on other systems and teams, saving considerable time and effort. More importantly, it encourages a culture of interoperability and collaboration, fostering a more streamlined and efficient operational flow. The satisfaction and positive feedback from the teams have been testament to the success of this venture, reinforcing our conviction that the best and cost-efficient solutions are often the simplest ones.